8 minutes
Microservice Project – Step 6

Table of Contents
Nessa etapa, criaremos as filas que necessitamos para a comunicação com os microservices. Iremos instanciar a classe de configuração do Rabbit para inicializar juntamente com a API, estabelecendo uma conexão, e criando automaticamente as filas para consumo. Veremos também como funciona o recurso RPC, que irei detalhar posteriormente como funciona. Também, será explicado cada funcionalidade da criação da fila do rabbit que utilizaremos. Por fim, mostrarei no manager, a parte visual de como irá ficar nossas filas. No final dessa etapa, será resumido como funcionará o código, por uma visão geral.
Dentro da pasta API, crie uma subpasta chamada rabbitmq_controller com o arquivo rabbit_queues.py.
MS-application
└───API
│ docker-compose-api.yml
│ Dockerfile
│ requirements.txt
│ server.py
│
├───config
│ database_connection.py
│ rabbitmq_connection.py
│ redis_connection.py
│ __init__.py
│
└───rabbitmq_controller
rabbit_queues.py
__init__.py
Queues
O que iremos criar será algo relativamente simples. Como vamos ter os microservices users e orders, nossa API terá que se comunicar com eles de alguma maneira. Para isso, utilizaremos o message broker do rabbit. A ideia é termos duas filas para comunicação entre API/Serviço, porém existe um pequeno detalhe, como em alguns casos que iremos fazer uma consulta no banco de dados, desejando enviar um response ao usuário. Nas filas do rabbit existe um sistema de ACK para confirmação de entrega de mensagens ao destinatário, porém é algo simples, não podendo ter uma personalização da mensagem de confirmação.
O que precisaremos fazer, será utilizar um recurso chamado Remote Procedure Call (RPC). Que consiste em um remetente enviar uma mensagem e aguardar o destinatário processar a informação, para que depois possa retornar uma resposta. Resumindo, uma comunicação assíncrona. Sendo assim, será necessária uma fila auxiliar para transmitir esse response. Abaixo há uma ilustração da arquitetura que iremos criar.
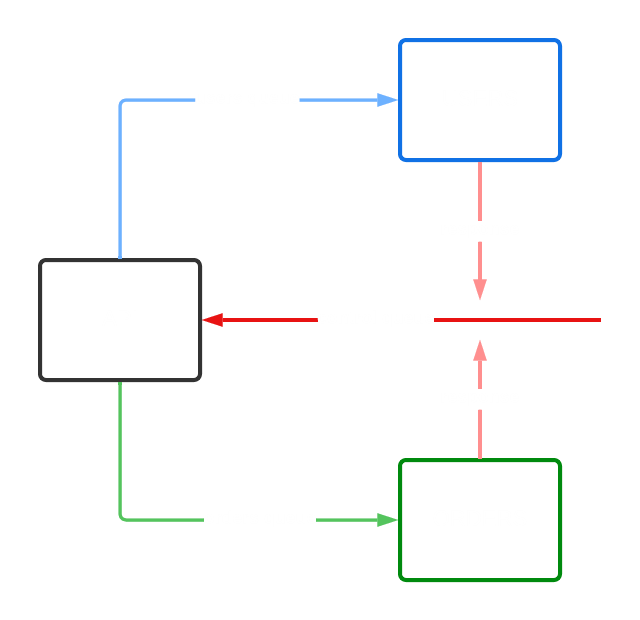
Agora que temos a arquitetura do que precisamos construir, podemos começar.
Primeiramente precisamos fazer a sequência de imports das bibliotecas, e importar a classe da configuração do rabbit, que fizemos no passo anterior.
import pika, uuid, threading, time
from config.rabbitmq_connection import RabbitConnection
Logo após, vamos criar uma classe chamada RabbitQueue(), contendo duas variáveis que iremos utilizar posteriormente.
class RabbitQueue():
internal_lock = threading.Lock()
queue = {}
No método __init__.py vamos ter crias o seguinte atributo. Primeiro precisamos instanciar a classe de conexão com o servidor Rabbit para posteriormente criar as filas. Por enquanto precisamos saber só disso, os demais atributos irão ser abordados posteriormente.
def __init__(self) :
self.RMQ = RabbitConnection()
result = self.RMQ.channel.queue_declare(queue='', exclusive=True)
self.callback_queue = result.method.queue
self._create_process_thread()
Agora, criaremos um método chamado create_queues(), pra criar as filas que precisamos consumir. Para isso será utilizado a o atributo channel, da classe de conexão, e a função queue_declare, para declarar as filas.
def create_queues(self):
self.RMQ.channel.queue_declare(queue='user')
self.RMQ.channel.queue_declare(queue='order')
print(' [✓] Queues created successful!')
Vamos criar agora, o método chamado _create_process_thread(), ele será responsável por criar uma thread de processamento, fazendo com que o consumo de diferentes processos seja independente.
def _create_process_thread(self):
thread = threading.Thread(target=self._process_data_events)
thread.setDaemon(True)
thread.start()
No método rpc_async(), terá como parâmetros o payload , que será passado a informação que será lançado na fila, e o parâmetro route, que será o nome da fila que será utilizada.
Nesse método faremos a configuração da fila de controle, que citei anteriormente. Para isso, será criado um ID para fila, utilizando a biblioteca uuid.
No with, será verificado a variável internal_lock que criamos, nela é atribuído um bloqueio primitivo. Uma vez que um thread adquiriu um bloqueio, as tentativas subsequentes de adquiri-lo bloqueiam, até que ele seja liberado. Após isso, será passada a route com o nome da rota, e como propriedade há um reply_to, que é um recurso que permite que clientes RPC (solicitação/resposta) evitem declarar uma fila de resposta por solicitação, comumente usados para nomear uma fila de retorno de chamada. Nele é passado o atributo callback_queue que foi criado no __init__.
Também há o correlation_id, que é útil para correlacionar respostas RPC com solicitações. É passado o id criado anteriormente, que será o nome da fila de controle.
E por fim, o body, contendo a informação passada através do payload.
def rpc_async(self, payload, route):
corr_id = str(uuid.uuid4())
self.queue[corr_id] = None
with self.internal_lock:
self.RMQ.channel.basic_publish(exchange='',
routing_key=route,
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=corr_id,
),
body=payload)
return corr_id
No método _on_response() será apenas armazenado o response da fila em um dicionário, passado como key, a ID que foi criado no metodo rpc_async, e no value o body do response.
def _on_response(self, ch, method, props, body):
"""On response we simply store the result in a local dictionary."""
self.queue[props.correlation_id] = body
O método _process_data_events(), será responsável por ser uma espécie de vigia de eventos da fila de controle, e marcar um ACK ao evento, para consumi-lo.
def _process_data_events(self):
self.RMQ.channel.basic_consume(
queue=self.callback_queue,
on_message_callback=self._on_response,
auto_ack=True,
)
while True:
with self.internal_lock:
self.RMQ.connection.process_data_events()
time.sleep(0.1)
Consumo da classe RabbitQueue e ConnectionDatabase
Agora, só precisamos apontar a classe RabbitQueue no arquivo server.py para que possamos começar a consumir as filas que criamos.
Antes de tudo, devemos importar todas as bibliotecas que precisaremos.
import json,time
from flask import Flask, request
from config.database_connection import ConnectionDatabase
from rabbitmq_controller.rabbit_queues import RabbitQueue
Fora da classe Api_server iremos instanciar RabbitQueue que criamos, a uma variável chamada rabbit_queues. Ela ficará fora da classe pois queremos que ela seja vista globalmente no arquivo. Dentro da classe Api_server, criaremos o construtor __init__ e chamaremos o método create_queues, para criar as filas, e também iremos chamar a classe ConnectionDatabase ,criada no Step5. Isso será responsável por se conectar aos dois servidores de serviço e criar as tabelas no banco, e filas no rabbit.
rabbit_queues = RabbitQueue()
class Api_server():
app = Flask(__name__)
ConnectionDatabase()
rabbit_queues.create_queues()
Uma pergunta que você pode estar se questionando é "porque não criar o atributo app e a criação das filas do rabbitdentro de um __init__?".
Bom, na maioria dos projetos que podem ser encontrado na internet relacionada ao Flask, você simplesmente irá se deparar com um arquivo com uma rota chamando uma função abaixo, sem segredos em relação a isso. Podemos compreender que o Flask não foi feito para seguir os padrões de Orientação a Objetos, tanto que é, que se você tentar colocar um "self", na def abaixo da rota, simplesmente não irá funcionar. Visto isso, apenas atribui a estrutura de rotas e funções dentro de uma classe como uma boa prática, porém, não é necessário fazer isso caso você não queira.
Agora, respondendo à pergunta, o simples fato de colocar um "self" antes do app ou da criação das filas, já faria com que todo o código parasse de funcionar, visto que no marcador @ não iria identificar o "self.app" que foi criado no init.
Routes
Na chamada das routes, precisaremos invocar o método rpc_async para que possamos enviar o playload para a fila desejada. Para isso, utilizarei o mesmo exemplo que foi utilizado no Step4, com a rota /user/create_user/.
Chamaremos o método rpc_async, passando como parâmetros o payload recebido na requisição, e a string "user", que será a fila que será enviada a mensagem. Tudo isso será atribuído para uma variável chamada corr_id, que terá como return o correlation_id. Após isso, ficará sendo verificado o atributo queue, da classe RabbitQueue, se contêm alguma informação. Caso tenha, essa informação será retornada ao usuário.
@app.route("/user/create_user/", methods=['POST'])
def create_user():
if request.method == 'POST':
payload = request.get_json()
corr_id = rabbit_queues.rpc_async(json.dumps(payload),"user")
while rabbit_queues.queue[corr_id] is None:
time.sleep(0.1)
return {'Status': 200, 'Message': json.loads(rabbit_queues.queue[corr_id])}
else:
return {'Status': 404, 'Message': 'Erro no envio do method'}
Resumo da Funcionalidade
E chegamos ao fim do envio de mensagens a fila. Como podem perceber, são muitas coisas divergentes sendo processadas, enviadas e recebidas ao mesmo tempo, podendo ser um pouco complexo de entender inicialmente. Basta montar o condigo na ordem que foi mostrada acima, e olhá-lo de uma visão panorâmica, que as peças se encaixarão.
Para facilitar um pouco mais, vou resumir em tópicos o que vai acontecer quando enviarmos uma mensagem para alguma fila.
- Será chamado o método rpc_async passando a mensagem e a fila que deverá ser enviada.
- No __init__ da classe RabbitQueue, estabelecemos uma conexão com servidor Rabbit, e declaramos um callback_queue exclusivamente para receber resposta da fila de controle. É criada uma thead que ficará monitorando a fila de controle.
- No rpc_async é onde será feita a solicitação RPC.
- Dentro do rpc_async é gerado um correlation_id exclusivo e o salvamos. O método _on_response usará esse valor para criar um dicionário, que será atribuído a key.
- Também no método rpc_async, publicamos a mensagem com duas propriedades, reply_to e correlation_id.
- O callback_queue será marcado para que possamos receber respostas RPC.
- O _process_data_events , terá a função de ficar monitorando a fila de controle para poder gravar o response do parâmetro on_message_callback, passado para o _on_response.
- No _on_response , será montado um dicionário, que irá conter o correlation_id e o body capturado da fila de controle. O body será o response da fila.
- Por fim, no arquivo server.py, será verificado se a variável queue contém alguma informação para ser repassada como response da requisição a API.
Agora que já fizemos tanto a parte de conexão e criação das tabelas do banco de dados, quanto a conexão e criação das filas do rabbit, vou fazer um teste inicializando a API, verificando se todas as coisas que criamos estão rodando como deveriam.
Como quero testar utilizando os servidores que já estão rodando na instância OCI, liberei as portas dos serviços para que eu possa fazer o teste localmente de meu computador.
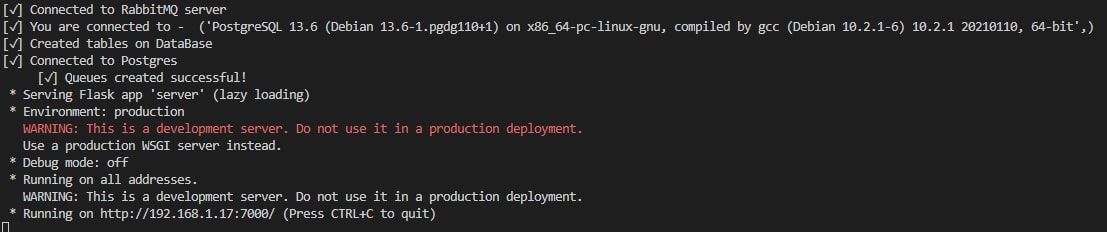
Após rodar a API aparecerão algumas informações como a conexão com o rabbit e a criação das filas feitas, e também informações sobre o Flask.
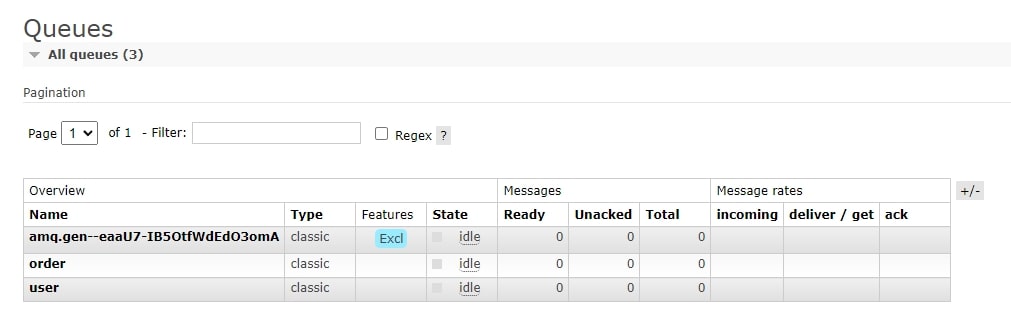
Já na Manager do rabbit podemos ver a criação das filas order e user, juntamente com a fila de controle.
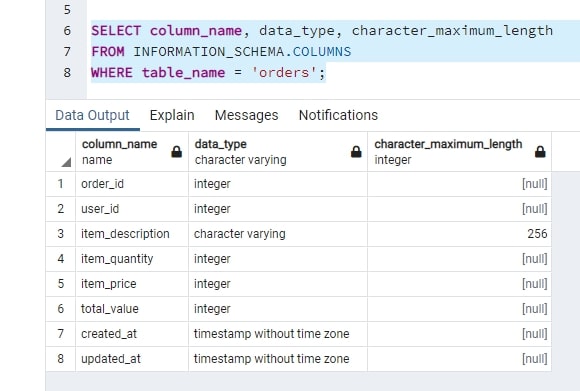
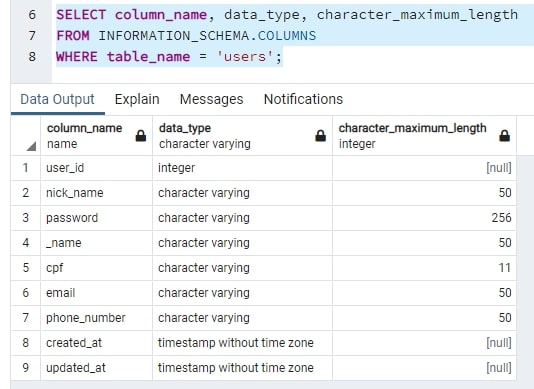
E no PgAdmin fiz um select para verificar se as tabelas foram criadas.
1614 Words
2022-07-07 09:01