8 minutes
Microservice Project – Step 8

Table of Contents
No passo anterior concluímos a arquitetura do Microsserviço, e fizemos a conexão com os serviços do Rabbit e Postgres. Agora, vamos fazer a lógica do sistema de usuário, onde iremos diferenciar as interações com o banco de dados através de uma tag, enviada pela API, e dependendo da interação de for solicitada, haverá o acionamento de uma função equivalente a solicitação.
Na pasta raiz da aplicação MS-Application, vamos criar os seguintes arquivos:
MS-application
└───MS1
│ docker-compose-microservice1.yml
│ Dockerfile
│ main.py
│ requirements.txt
│
├───config
│ database_connection.py
│ rabbitmq_connection.py
│ __init__.py
│
├───database_controller
│ postgres_worker.py
│ __init__.py
│
└───rabbitmq_controller
rabbit_worker.py
__init__.py
Tag API
Antes de começarmos a codar, vamos entender o cenário onde paramos. Temos uma API que recebe as informações de uma criação de usuário, por exemplo, e envia essas informações para o microsserviço. Para o microsserviço entender o que deve ser feita com aquelas informações recebidas, a API deverá enviar uma tag juntamente ao corpo das informações, que posteriormente será identificada. Entendendo esse fluxo, vamos voltar ao código da API e fazer essa pequena alteração da inserção da tag.
No arquivo server.py, vamos ao método de criação de usuário que abordamos nos Steps anteriores, e inserir ao payload que recebemos item chamado type, com o valor create.
@app.route("/user/create_user/", methods=['POST'])
def create_user():
if request.method == 'POST':
payload = request.get_json()
payload['type'] = 'create'
corr_id = rabbit_queues.rpc_async(json.dumps(payload), "user")
while rabbit_queues.queue[corr_id] is None:
time.sleep(0.1)
return {'Status': 200, 'Message': json.loads(rabbit_queues.queue[corr_id])}
else:
return {'Status': 404, 'Message': 'Erro no envio do method'}
Controlador DataBase
O controlador do database será o responsável por fazer o famoso CRUD. CRUD é a composição da primeira letra de 4 funções básicas de um sistema que trabalha com banco de dados:
✔️ C: Create (criar) - criar um novo registro.
👀 R: Read (ler) - ler (exibir) as informações de um registro.
♻️ U: Update (atualizar) - atualizar os dados do registro.
❌ D: Delete (apagar) - apagar um registro.
No desenvolvimento desse estágio mostrarei apenas uma interação com o banco de dados, visto que o desenvolvimento é muito complexo, e a leitura ficará muito maçante. O que faremos agora será a inclusão de um usuário ao banco. Para isso, devemos inserir as informações através de um comando SQL.
Primeiramente devemos importar todas as dependências necessárias, que serão a conexão com o banco, feita no database_connection.py, e a biblioteca datetime.
from config.database_connection import ConnectionDatabase
from datetime import datetime
Vamos criar uma Classe chamada PostgresWorker , com o construtor __init__ contendo a conexão com o banco, captura do horário atual, e a formatação da data.
def __init__(self):
self.PSQL = ConnectionDatabase()
self.date_time = datetime.now()
self.date_time_formate = self.date_time.strftime('%Y/%m/%d %H:%M')
Manipulação de datas
Algo a ser ressaltado! No código que iremos desenvolver, fiz todas as manipulações de datas usando o formato DATE, para uma explicação mais dinâmica e simples. Contudo, em projetos reais é MUITO RECOMENDADO a utilizar o padrão Unix Timestamp.
Unix Timestamp é um ponto fixo na história da computação, onde em 1º de janeiro de 1970 às 00:00 foi iniciado a contagem dos segundos. Essa data é considerada o início dos tempos pelo Linux. O motivo da recomendação do uso desse tipo de formato é pelo fato de o valor retornado do timestamp ser um float numeric. Sendo assim, é facilmente manipulado de forma binária e é muito curto e rápido de ser calculado.
A imagem abaixo mostra como uma determinada data e hora é representada em diferentes formatos.
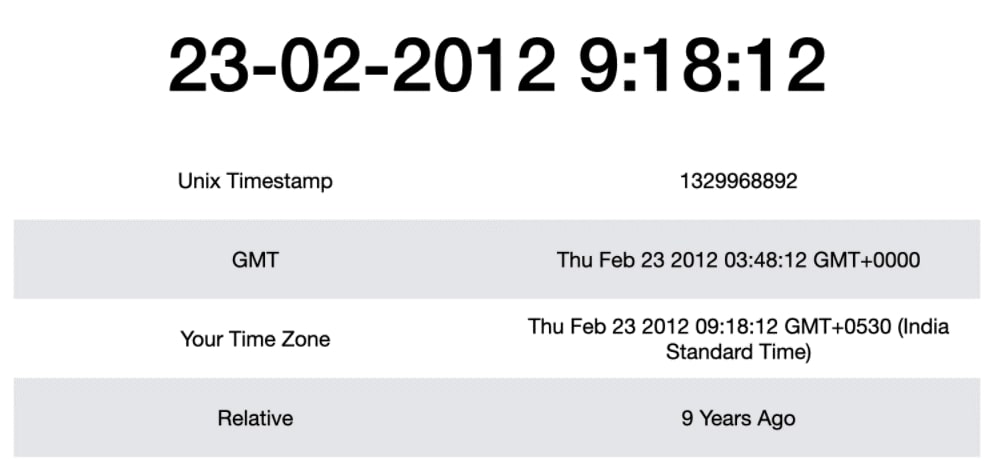
Imagem 1: https://pynative.com/python-timestamp/
Agora que entendemos a importância do uso do formato Unix Timestamp, podemos continuar com o desenvolvimento.
Insert_user
O que faremos agora será criar uma função chamada insert_user que fará a inserção/criação de usuário no nosso banco de dados. O método receberá como parâmetro data, que serão os dados para fazermos a interação com o banco.
Dentro do método teremos a variável query_insert que conterá a query para a execução do comando. Na variável vars_query terão as informações recebidas da fila, que serão inseridas da query. A função "cursor.execute(query_update, vars_query)" é responsável pela execução do comando, onde pegará a query_update, inserirá os valores de vars_query, e executará a instrução. A função "connection.commit" é responsável por fazer as alterações do banco para a persistência do database. Por fim, é retornado alguma informação. Tudo isso ficará dentro de um try-except, para caso haja alguma falha na interação com o banco, seja lançado um except com o erro.
Como esse caso é apenas uma inserção no banco, apenas retornará uma mensagem ao usuário. Entretanto em casos de retorno de alguma informação do banco ao usuário, essas informações serão passadas no return.
def insert_user(self, data):
try:
query_insert = 'INSERT INTO users (full_name, nick_name ,password ,cpf , email, phone_number, created_at, updated_at)VALUES (%s,%s,%s,%s,%s,%s,%s,%s)'
vars_query = (data['name'], data['nick_name'], data['password'], data['cpf'],
data['email'], data['phone_number'], self.date_time_formate, self.date_time_formate)
self.PSQL.cursor.execute(query_insert, vars_query)
self.PSQL.connection.commit()
print('[✓] INSERTION DONE IN POSTGRES!')
return '[✓] User created successfully! '
except Exception as error:
print(error)
return f'[X] ERROR INSERTING IN POSTGRES! {error}'
finally:
self.PSQL.cursor.close()
Show_all_user
Para exemplificar uma situação em que precisamos retornar uma informação do banco de dados para o usuário, vamos criar a função show_all_user. A estrutura da função será muito semelhante a que criamos acima. Teremos somente uma query de instrução que será um select de toda a tabela. Serão capturadas as informações através do comando "cursor.fetchall", e manipuladas para mostrar mais organizado ao usuário. Tudo isso ficará dentro de um try-except, para caso haja alguma falha na interação com o banco, seja lançado um except com o erro.
def show_all_user(self):
try:
sql_select_query = 'SELECT * FROM users'
self.PSQL.cursor.execute(sql_select_query)
record = self.PSQL.cursor.fetchall()
self.PSQL.connection.commit()
dict_all_users = []
for index in range(len(record)):
dict_response = {
'nick_name': record[index][1],
'name': record[index][3],
'email': record[index][5],
'phone_number': record[index][6],
'created_at': str(record[index][7]),
'updated_at': str(record[index][8])
}
dict_all_users.append(dict_response)
print('[✓] SELECT DONE SUCCESSFULLY IN POSTGRES!')
return {'users': dict_all_users}
except Exception as error:
print(error)
return f'[X] ERROR ON SELECT IN POSTGRES! {error}'
finally:
self.PSQL.cursor.close()
Com isso, podemos ter uma base de como fazer o nosso CRUD. As demais funções poderão ser visualizadas no repositório git do projeto.
Métodos Criados
Os métodos precisaremos criar são:
- insert_user – Criação de usuário;
- alter_user – Alterar informações do usuário exceto senha;
- alter_password – Alterar senha do usuário;
- show_all_user – Mostrar todos os usuários cadastrados;
- show_one_user – Mostrar informações de um usuário através do NickName;
- delete_user – Deletar um usuário através do NickName;
- information_user – Selecionar todas as informações de um usuário;
- take_pass – Selecionar senha do usuário.
Controlador Rabbit
O controlador do rabbit será o responsável por identificar a tag recebida e irá disparar uma função para a interação com o banco de dados. Contudo o retorno do bando de dados deve ser retornado também ao usuário que consumiu a API, para isso, iremos publicar esse response através da fila de controle que criamos no Step6.
No arquivo rabbit_worker.py vamos iniciar importando as dependências.
import json, pika
from database_controller.postgres_worker import PostgresWorker
Vamos criar uma classe chamada RabbitWorker, e em seu construtor __init__ criaremos um atributo vazio chamada self.data.
class RabbitWorker():
def __init__(self):
self.data = ''
Logo abaixo, criaremos o método que chamamos no arquivo main.py, chamado de call-back. Ele é o responsável por processar os dados recebidos, e retornar a fila de controle, um response ao usuário. Nos parâmetros iremos deverá ter ch, method, props e body. No atributo self.data iremos carregá-lo com as informações recebidas do body. Logo abaixo, criaremos uma variável onde chamaremos o metodo database_manipulation(self.data) que criaremos posteriormente. Após isso, através do atributo ch, iremos criar a parte da publicação da mensagem de response na fila de controle e dando um ACK na fila de controle.
def callback(self, ch, method, props, body):
self.data = json.loads(body)
response_work = self.database_manipulation(self.data)
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(
correlation_id=props.correlation_id),
body=json.dumps(response_work))
ch.basic_ack(delivery_tag=method.delivery_tag)
Como dito anteriormente, agora vamos criar o método database_manipulation, que é responsável por identificar a tag que há no corpo dos dados recebidos da API, e acionar os métodos contidos no arquivo postgres_worker.py para a fazer a ação solicitada da requisição.
O que faremos é bem simples. Quando for recebido uma mensagem na fila de usuário, a mensagem será consumida. Será identificado o type da mensagem, que no caso é nossa tag, e após isso, chamaremos uma função equivalente ao type, para executar um CRUD no banco de dados.
Essa identificação será através de um if-elif da informação "type", contida em data.
| Type | Function | Objective |
|---|---|---|
| create | insert_user | Criar usuário |
| update | alter_user | Alterar informações de usuário |
| update_password | alter_password | Alterar senha de usuário |
| show_all | show_all_user | Mostrar todos os usuários |
| show_one | show_one_user | Mostrar um usuário |
| delete_user | delete_user | Deletar um usuário |
def database_manipulation(self, data):
# start connection whith postgres
psql = PostgresWorker()
if data['type'] == 'create':
return psql.insert_user(data)
elif data['type'] == 'update':
return psql.alter_user(data)
elif data['type'] == 'update_password':
return psql.alter_password(data)
elif data['type'] == 'show_all':
return psql.show_all_user()
elif data['type'] == 'show_one':
return psql.show_one_user(data)
elif data['type'] == 'delete_user':
return psql.delete_user(data)
Resumo
Nesse passo fizemos uma pequena alteração na API, inserindo uma nova informação no payload que será o ponto crucial para a identificação da ação que deve ser feita no banco de dados. Criamos o database_worker onde há as funções de interação/manipulação do banco de dados, onde foi feito um CRUD. Foi explicado um pouco sobre o uso do UNIX Timestap para gravação de data-hora no banco de dados. Criamos o rabbit_worker, que é o responsável por identificar o que está sendo solicitado através da tag, pegar as informações recebidas e utiliza-la nas funções contidas no database_worker. Por fim, é publicado na fila auxiliar uma mensagem de response, onde o usuário receberá essa informação já processada.
1579 Words
2022-07-21 09:23